Nango is a code-first platform for building product API integrations. Customers connect their apps to Salesforce, Google Calendar, Slack, and a few hundred other APIs. Much of the code behind those integrations is written by our customers and deployed to us.
That code is untrusted, and can try to do anything: fetch an API, transform data, throw an exception, leak memory, or intentionally try to break out. We run more than 150 million of these functions a month across different workload shapes.
Our requirements for the code runtime
We run three very different workloads:
- On-demand calls (Actions): run for a user or agent, so they must start and finish fast. Cold starts hurt.
- Long-running jobs (Syncs): replicate data in the background, sometimes for hours across millions of records. They need resumable execution.
- Bursty events (webhooks): arrive in unpredictable spikes, so they have to absorb sudden floods.
Running untrusted code then adds more requirements:
- Isolation from our systems: a function must never reach our database, secrets, or internal network.
- Isolation between tenants: one customer’s code must not reach another’s, and one customer’s heavy job must not starve everyone else.
- Isolation between executions: A customer can have a mix of long and short-running jobs. Jobs should not fight for the same resources.
- Cost and elasticity: We will not pay for idle compute or hand-scale a fleet.
Meeting these requirements is not easy. Reducing cold starts means keeping environments warm, which costs money; long syncs need extended run time; spiky webhooks need cheap compute that scales from zero.
Every runtime we built had some tradeoffs but we’ve always tried to prioritize security.
We started with an in-process sandbox (vm2)
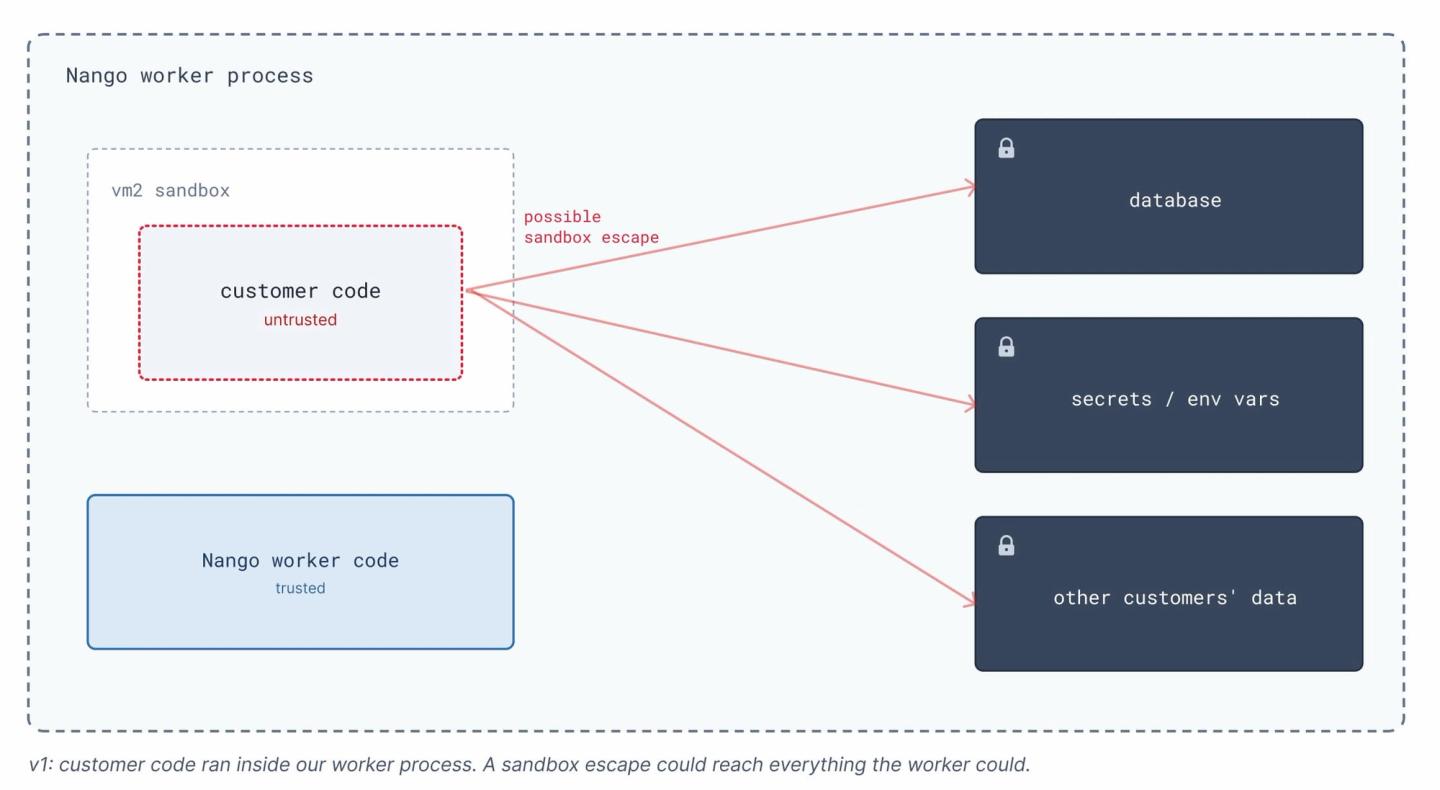
In our first years, we ran customer code inside vm2, a Node.js sandbox, in the same process as the worker that ran the job. The customer’s function executed right alongside our own code, and vm2 blocked it from our database, secrets, and other customers’ data. It was simple, and required no extra infrastructure.
Then, in 2023, vm2’s maintainer temporarily archived the project after a series of sandbox-escape vulnerabilities: code inside the sandbox could reach the host and run on the worker. A malicious integration could do the same to us.
We learned that an in-process JavaScript sandbox is not a real security boundary. Share a process with untrusted code, and you are one escape away from a serious problem.
Isolating untrusted code in a runner
So we stopped running customer code in the same process as anything that mattered.
We split the system into two. A dispatcher hands each customer’s code to a runner over HTTP, and a separate runner executes it. Each customer gets their own long-lived runner, scaled independently: more CPU or memory, or extra replicas for heavy accounts.
We also built an orchestration layer that spins up runners on demand, retires idle ones, and rolls out updates across hundreds of them. The scheduler behind the dispatcher initially ran on Temporal; we later moved it to Postgres (a separate story).
Crucially, runners get no direct database access. To read or write records, a function calls an SDK method like nango.batchSave(...) that goes to a separate persist service over the network; persist talks to the database, the runner never does. A runner holds the customer’s code and the minimum it needs, nothing more. We ran the runners as separate services on Render.

Moving to AWS Lambda
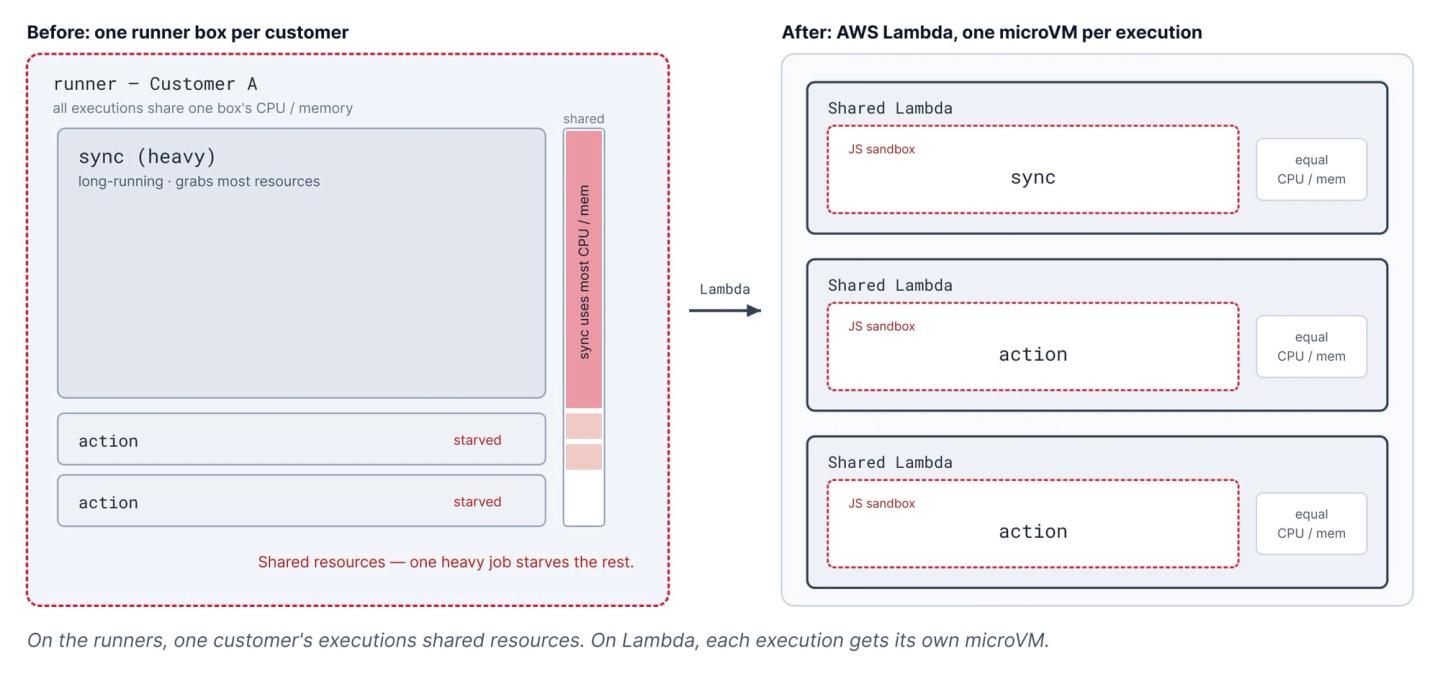
By late 2025, the runner model was struggling with resource fairness and observability. A runner ran all of a customer’s executions together, so one heavy job, say a connection replicating millions of records, could starve that customer’s other functions. And when a runner ran out of memory, we could not reliably say which of its thousands of functions caused it. We wanted to isolate each execution and observe each one.
AWS Lambda gave us both. With Lambda, each execution runs in its own hardware-virtualized microVM with its own kernel, far stronger than a shared process, and AWS handles the scaling. We had looked at other alternatives like Knative and WASM-based runtimes, but they were similar to Lambda with far less maturity.
We started seeing improvements right away.
A memory/CPU issue now points to a single connection’s function, visible in that function’s own logs, instead of a vague “this runner is struggling,” and one bad code function no longer affects others. For a small team supporting hundreds of customers, this resulted in significant reductions in time spent debugging these issues.
However, there was a problem. A Lambda function runs for at most 15 minutes, and our syncs ran far longer. So we solved it on the product side: a 10-minute cap per run for syncs, and a checkpoints feature that lets a sync resume across runs instead of relying on one long execution. A resumable run beats a single 24-hour job anyway, since a job that dies at hour 23 and restarts from zero is its own kind of failure.
Tenant isolation on AWS Lambda
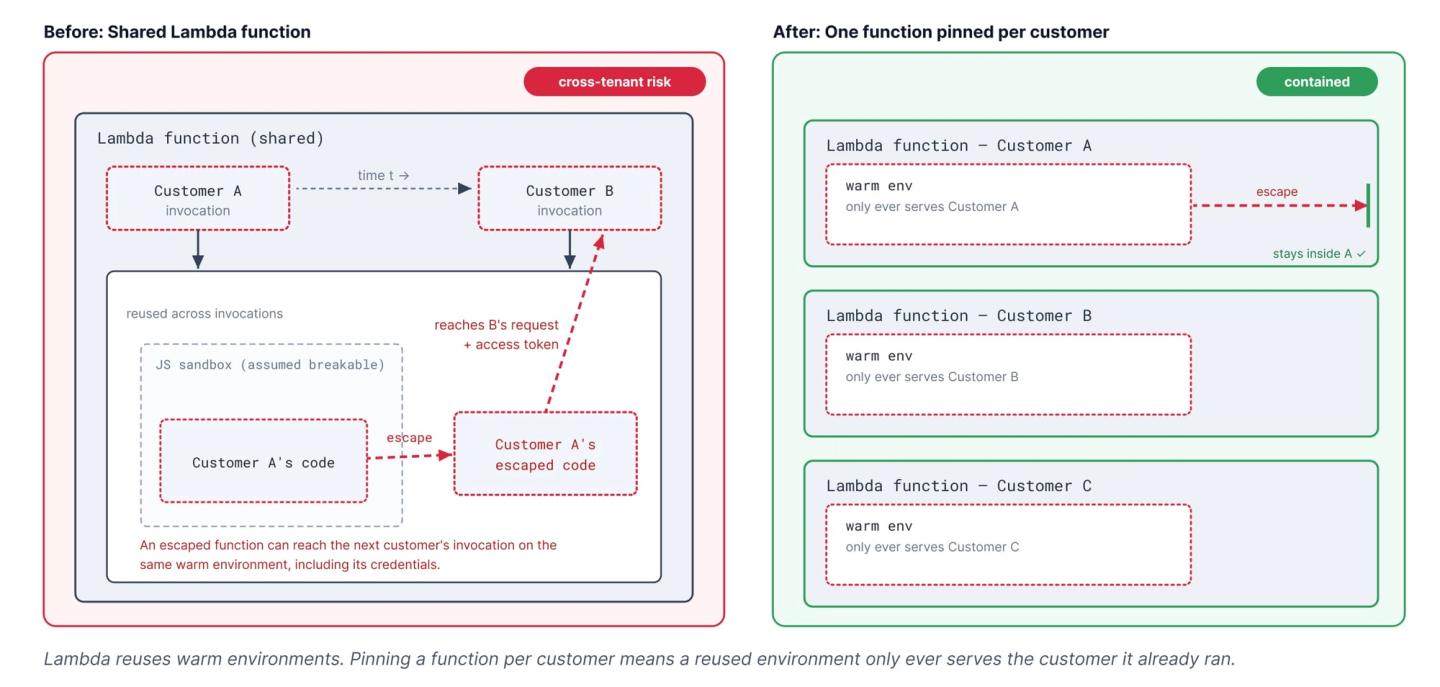
Lambda isolates executions but reuses environments to stay fast: when a function finishes, AWS may route the next invocation to that warm environment instead of starting a cold one. Environments are never shared across AWS accounts, and for most apps, reuse is not an issue. But for Nango, sharing Lambda environments means two different customers could land on the same warm environment, and with untrusted code, that is a real security risk.
We also run a JS sandbox inside each Lambda to limit what a function can do, but we know a determined attacker can escape it. In a shared environment, an escaped function could reach the next customer’s invocation, including the credentials passed in for it. Hardware isolation between executions does not help when the same environment serves two customers in turn.
Our fix was to align the isolation boundary with the customer. Each customer’s executions are pinned to their own Lambda functions, so a warm environment is only ever reused for the customer it already served. An escape stays contained to what that customer already controls.
We debated whether this is the right path:
Per-customer functions cold-start more often. A shared Lambda function stays warm because it is always busy; a single-customer Lambda goes idle more often. In our rollout, cold starts went from well under 1% of invocations to roughly 9%, each adding several seconds, which is very visible in an action’s request path. So we keep functions on paid plans warm with periodic no-op invocations.
Our team had multiple views:
- One view: pinning per customer and keeping functions warm rebuilds the same always-on model we had with runners, with mechanisms that work around Lambda’s limits. We are bending a runtime to fit needs it was not built for; we should instead focus on building a sandbox strong enough that tenant isolation is unnecessary.
- The other: it is sound, incremental progress. Take the isolation Lambda gives us, change as little else as possible, close the biggest risk now, and keep the harder sandboxing work on the roadmap.
Both are right, which makes it a real trade-off. A sandbox where escaping gains nothing would remove the need for tenant isolation and warming. But we are not there yet. In the meantime, tenant-isolated Lambdas make the runtime safe enough to run at scale.
How others isolate untrusted code
Running untrusted code is no longer niche: AI agents generate and run it on the fly, and products have appeared to host it (E2B, Modal, Fly, Cloudflare). Most of them land where we did, on hardware-level isolation: E2B and Fly use microVMs, Modal uses gVisor.
Cloudflare Workers uses V8-isolate and accepts a weaker boundary; the 2025 runc container-escape bugs were a reminder that a shared kernel is not secure. V8 is also not a good fit for us, as our customer functions import arbitrary npm packages that V8 cannot safely sandbox.
Lessons from running untrusted code at scale
A few lessons that our team highlighted:
- Know which boundaries actually stop an attacker: an in-process sandbox is easy and feels safe, but it is escapable, so we should not count it as isolation.
- Draw the security line where your product needs it: ours was that the customer code never reaches our systems, and one customer code never reaches another. Finer-grained isolation came later.
- Fit the runtime to the workload, and call workarounds what they are: Acknowledging workarounds keeps them from quietly becoming the architecture.
- Prefer short, resumable work over long-running jobs: a resumable run survives failures, works better for rate-limits, and is, in general, more practical.
Running other people’s code safely is work that is never quite finished. The next step we are tackling is tighter isolation down to the individual code function, so the Lambda boundary wraps a single function, and there is even less to reach if something breaks out.
We are a small team running this in production for hundreds of companies, and Nango is open source. If problems like this are your kind of work, we are hiring.